
في عالم اليوم الذي يتسارع فيه التقدم التكنولوجي، أصبح الذكاء الاصطناعي (AI) جزءًا أساسيًا من عمليات الأعمال. وفقًا لأحدث بحث صادر عن شركة ماكينزي، يستخدم 78% من المنظمات الذكاء الاصطناعي في وظيفة أعمال واحدة على الأقل، وهذا ارتفاع كبير من 55% فقط في العام الماضي، بينما يستخدم 65% منها الذكاء الاصطناعي التوليدي بانتظام. هذا الانتشار السريع يشير إلى أن الشركات تدرك إمكانيات الذكاء الاصطناعي، وأصبح الوقت مناسباً لاستغلال حلول AI مخصصة تفهم بياناتك وعملياتك الخاصة بشكل دقيق.
في هذا الدليل الشامل حول تدريب ChatGPT على بياناتك الخاصة، سنستعرض كل ما تحتاج إلى معرفته لتحويل أداة AI عامة إلى مساعد معرفي شخصي يفهم احتياجات عملك ومعلوماتك الفريدة. سنشرح الأمور ببساطة وتفصيل، مع توسيع الشرح لكل نقطة لمساعدتك على فهمها جيدًا، سواء كنت مبتدئًا أو محترفًا في مجال التقنية.
إليك ما سنغطيه في هذا المقال:
- لماذا تحتاج إلى تدريب ChatGPT على بياناتك الخاصة؟
- الطرق الثلاث الرئيسية لتدريب ChatGPT: Custom GPTs (مشروعات ChatGPT)، Fine-tuning (التعديل الدقيق)، وRAG (التوليد المعزز بالاسترجاع).
- عملية خطوة بخطوة لتنفيذ مشروعات ChatGPT.
- سير العمل الكامل للتعديل الدقيق مع إرشادات إعداد البيانات.
- كيفية إنشاء مجموعات بيانات عالية الجودة بتنسيق JSON المناسب.
- القيود الرئيسية لمشروعات ChatGPT وطريقة التعديل الدقيق.
بنهاية هذا المقال، ستتمكن من فهم أي طريقة تدريب تناسب احتياجاتك الخاصة، ميزانيتك، ومهاراتك التقنية، بالإضافة إلى اكتشاف بديل أفضل يجمع أفضل الميزات دون القيود المعتادة. دعونا نبدأ الرحلة معًا!
لماذا تحتاج إلى تدريب ChatGPT على بياناتك الخاصة؟
يمتلك ChatGPT معرفة واسعة حول مواضيع متنوعة، لكنه لا يعرف شيئًا عن عملك الخاص، وثائقك، أو معلوماتك الفريدة. تدريبه على بياناتك يجعله أكثر فائدة ودقة لاحتياجاتك اليومية. دعونا نبسط هذا: تخيل ChatGPT كمعلم عام يعرف الكثير عن التاريخ والعلوم، لكنه لا يعرف تفاصيل مدرستك أو طلابك. عندما تقدم له بياناتك، يصبح مثل معلم متخصص في مجالك.
السبب الرئيسي هو الحصول على إجابات أفضل. عندما يعمل ChatGPT مع بياناتك، يمكنه تقديم ردود تتوافق مع أسلوبك، تتبع قواعدك، وتستخدم معلوماتك الخاصة. هذا يقلل من الأخطاء ويزيد من الفائدة. على سبيل المثال، إذا كنت تدير شركة تجارية، يمكن للـ AI الرد على استفسارات العملاء بناءً على سياساتك الداخلية بدلاً من معلومات عامة قد تكون خاطئة.
كما أن بياناتك تحتوي على تفاصيل لم يرها ChatGPT من قبل، مثل سياسات الشركة، العمليات الداخلية، معلومات العملاء، والمعرفة المتخصصة. إضافة هذه المعلومات تساعد الـ AI على فهم سياقك بشكل أفضل، مما يجعل تفاعلاته أكثر ذكاءً وتخصيصًا.
الفوائد الرئيسية :
- دقة أعلى: الإجابات تأتي من معلوماتك الموثقة بدلاً من بيانات الإنترنت العامة، التي قد تكون قديمة أو غير دقيقة. على سبيل المثال، إذا كانت بياناتك تشمل أحدث أسعار منتجاتك، سيقدم ChatGPT أرقامًا صحيحة دون الحاجة إلى التحقق اليدوي.
- أسلوب متسق: يتعلم الـ AI كيفية الكتابة والرد بالطريقة التي تفضلها، مثل استخدام لغة رسمية للتقارير أو مرحة للتسويق. هذا يضمن أن جميع الردود تتناسب مع هوية علامتك التجارية.
- خصوصية المعلومات: تبقى بياناتك الحساسة تحت سيطرتك، دون مشاركتها مع خوادم خارجية غير ضرورية. هذا مهم جدًا للشركات التي تتعامل مع بيانات شخصية أو سرية.
- سير عمل أسرع: لا تحتاج إلى شرح الخلفية في كل مرة؛ الـ AI يتذكر سياق عملك. تخيل توفير الوقت في اجتماعات أو استفسارات يومية!
- معرفة متخصصة: يتعامل مع مصطلحات صناعية محددة، مثل مصطلحات طبية أو هندسية، دون الحاجة إلى تعريفها كل مرة.
- معلومات محدثة: يستخدم بياناتك الحالية بدلاً من تدريب الـ AI القديم، مما يضمن دقة الإجابات في بيئات متغيرة مثل السوق المالي.
تدريب ChatGPT على بياناتك يحوله من أداة عامة إلى مساعد متخصص يفهم احتياجاتك ويعمل بكفاءة أعلى في مهامك اليومية.
كيف يمكنك تدريب ChatGPT على بياناتك الخاصة؟
يمكنك تعليم ChatGPT العمل مع بياناتك الخاصة باستخدام ثلاث طرق رئيسية. كل طريقة تعمل بشكل مختلف وتناسب احتياجات متنوعة. الاختيار يعتمد على أهدافك، ميزانيتك، ومهاراتك التقنية. دعونا نشرح كل طريقة بتفصيل لمساعدتك على اتخاذ قرار مستنير.
الطرق المتاحة للتدريب:
Custom GPTs (مشروعات ChatGPT)
هذه الطريقة تسمح لك برفع الملفات وإنشاء مساعد AI شخصي. يمكنك إضافة وثائق، جداول بيانات، أو ملفات نصية مباشرة إلى ChatGPT. النظام يقرأ بياناتك ويرد على الأسئلة بناءً عليها. هي طريقة بسيطة مثل تحميل ملفات إلى Google Drive، لكن مع قدرة على التفاعل الذكي.
- تعمل مع ملفات تصل إلى 20 ميغابايت لكل ملف.
- لا تحتاج إلى مهارات برمجة.
- إعداد سريع في دقائق.
- مقتصرة على مستخدمي ChatGPT Plus.
Fine-tuning (التعديل الدقيق)
هذه الطريقة تدرب نموذج الـ AI باستخدام بياناتك. النظام يتعلم أنماط من معلوماتك ويصبح أفضل في المهام التي تريدها. تقدم OpenAI هذه الخدمة عبر API الخاص بها. تخيلها كتعديل سيارة لتصبح أسرع في سباق معين؛ تغير سلوك النموذج بشكل دائم.
- تغير سلوك النموذج بشكل دائم.
- تتطلب معرفة تقنية.
- تكلف أكثر ماليًا.
- تناسب المهام المحددة.
استخدم التعديل الدقيق عندما تريد أن يتصرف النموذج بطريقة معينة (أسلوب، تنسيق، سير عمل). لا تستخدمه عندما تريد تذكر حقائق كثيرة من وثائق كبيرة أو متغيرة – استخدم RAG (رفع/فهرسة الملفات) بدلاً من ذلك.
RAG (التوليد المعزز بالاسترجاع)
هذه الطريقة تربط ChatGPT بقاعدة بيانات تحتوي على معلوماتك. عند طرح سؤال، يبحث النظام عن البيانات ذات الصلة أولاً، ثم يولد إجابة بناءً عليها. هي مثل محرك بحث داخلي متصل بـ AI، مثالية للبيانات الكبيرة المتغيرة.
- تحافظ على البيانات منفصلة عن نموذج الـ AI.
- سهلة التحديث عند تغيير البيانات.
- تحتاج إلى مهارات برمجة.
- جيدة لكميات كبيرة من المعلومات.
- تتطلب إعدادًا تقنيًا وقاعدة RAG.
| الطريقة | الأفضل لـ | التكلفة | المهارات التقنية | حجم البيانات |
|---|---|---|---|---|
| Custom GPTs | الأعمال الصغيرة، الاستخدام الشخصي | منخفضة | لا شيء | صغير إلى متوسط |
| Fine-tuning | مهام محددة، أسلوب متسق | عالية | متوسطة | متوسط |
| RAG | قواعد بيانات كبيرة، بيانات متغيرة | متوسطة | متقدمة | كبير |
كيفية استخدام مشروعات ChatGPT
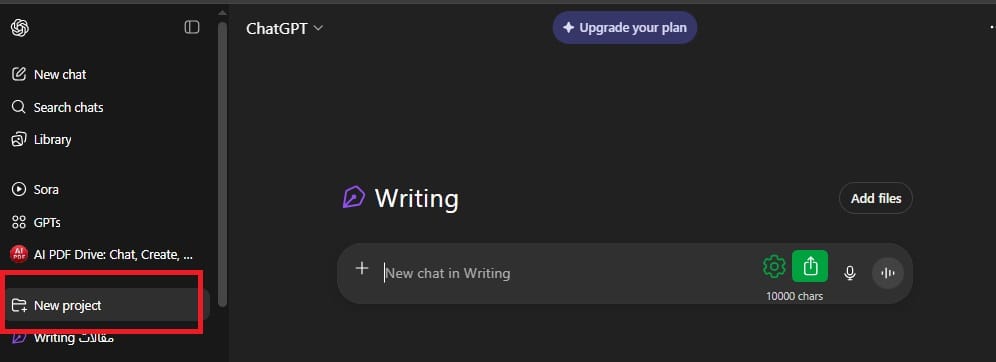
للوصول إلى مشروعات ChatGPT، يمكنك اختيار “مشروع جديد” في اللوحة اليسرى، ثم إضافة الملفات، الوثائق، إلخ، إليها والدردشة معها. كلما دردشت داخل المشروع، يرجع ChatGPT إلى البيانات من الوثائق المرفوعة.
بالإضافة إلى ذلك، يمكنك تعيين تعليمات مخصصة عامة لكل مشروع ChatGPT، تحدد كيف يجب أن يرد ChatGPT أو يقدم إجابات في كل مشروع لاستخدامات مختلفة. لكن مشروعات ChatGPT متاحة فقط لمستخدمي Plus
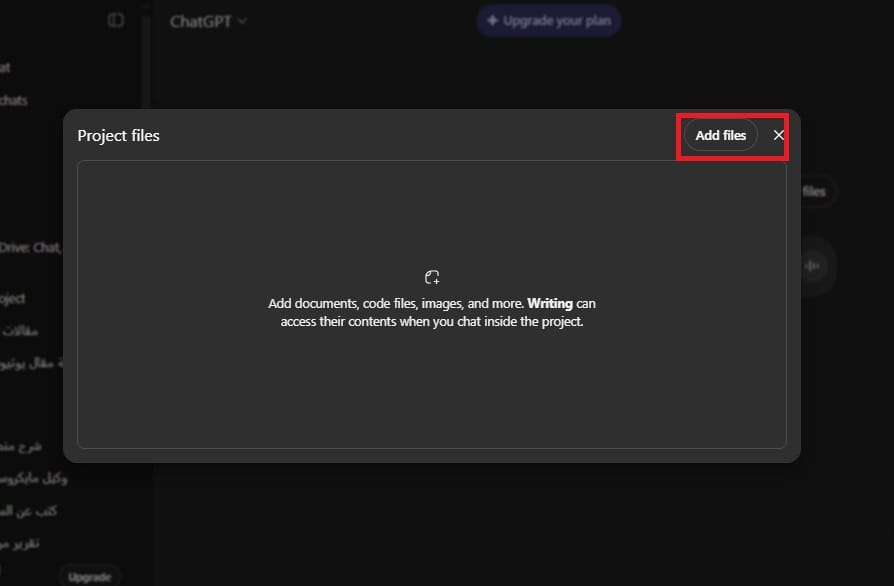
عملية خطوة بخطوة للتعديل الدقيق على ChatGPT
يسمح التعديل الدقيق على ChatGPT بتدريب النموذج ليعمل بشكل أفضل لاحتياجاتك الخاصة. هذه العملية تعلم الـ AI الرد بطرق تتوافق مع أسلوبك أو التعامل مع المهام التي تهمك. دعونا نشرح كل خطوة بتفصيل لتسهيل التنفيذ.
ملاحظة: هذه العملية لا تشمل إنشاء البيانات أو تحويلها إلى ملف JSONL.
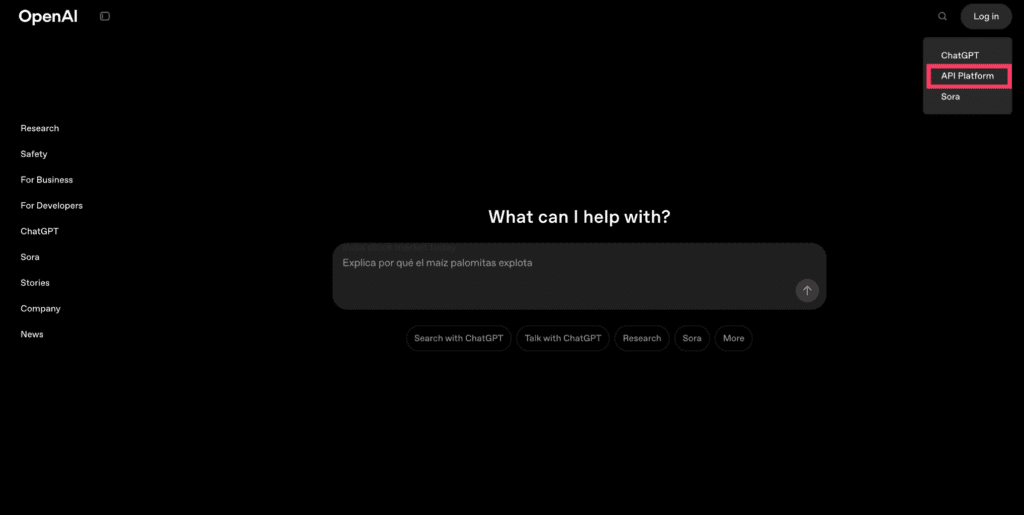
الخطوة 1: اذهب إلى موقع OpenAI وقم بتحريك الماوس فوق خيار الدخول؛ ستظهر قائمة منسدلة تحتوي على ChatGPT، API Platform، وSora. اختر خيار API Platform. (هذا ينقلك إلى لوحة التحكم التقنية حيث يمكنك الوصول إلى أدوات التطوير المتقدمة).
الخطوة 2: ستُوجه إلى لوحة التحكم في API Platform. على الجانب الأيسر، ابحث عن خيار “Fine-tuning” لـ ChatGPT، اختره، ثم اضغط على “create”. (هنا تبدأ عملية إنشاء نموذج مخصص؛ تأكد من أن لديك حسابًا نشطًا مع رصيد API).
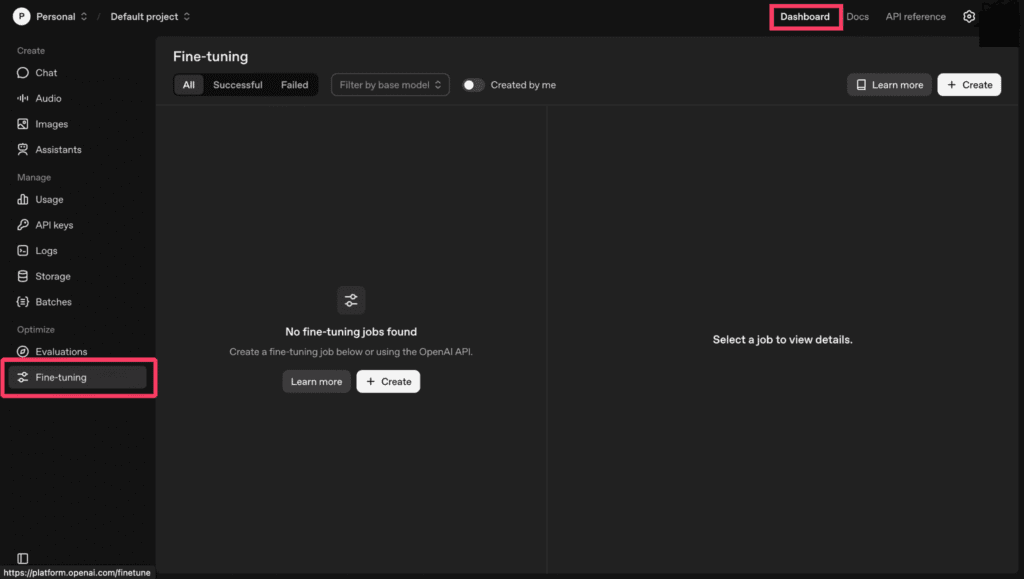
الخطوة 3: ستظهر لك جميع الخيارات للتعديل الدقيق، مثل النموذج المستخدم، اللاحقة (suffix)، وخيار رفع ملف JSON. إذا كنت جديدًا ولا تعرف الكثير عن الإعدادات، اختر نموذجك المفضل مثل GPT-4o أو GPT-3.5، أعطِ لاحقة (اسمًا للنموذج المعدل)، ارفع ملف JSON (الذي يحتوي على بيانات التدريب)، ولا تلمس أي خيارات إعداد أخرى. (اللاحقة تساعد في تمييز نموذجك، والبيانات يجب أن تكون جاهزة مسبقًا).
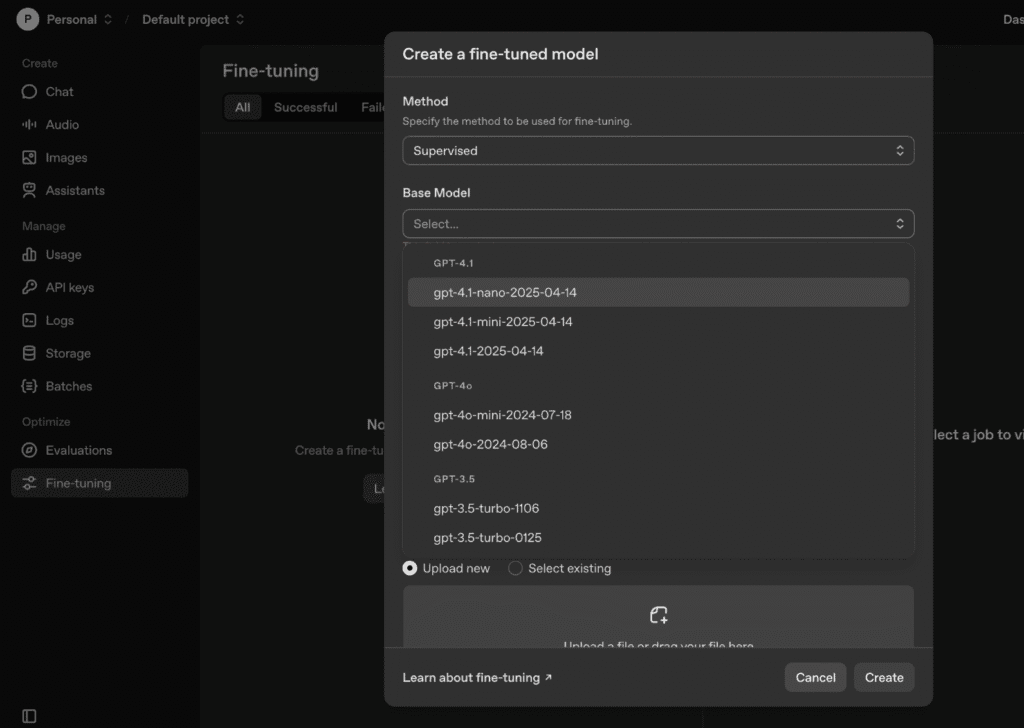
الخطوة 4: بمجرد رفع ملف JSONL الخاص بك، اضغط على “create”، وسيتم معالجة التعديل الدقيق. (هذه الخطوة قد تستغرق وقتًا حسب حجم البيانات؛ راقب التقدم في لوحة التحكم).
ملاحظة: تأكد من أن بيانات التدريب تحتوي على 10 أمثلة على الأقل؛ إذا كانت أقل من 10، ستفشل المعالجة.
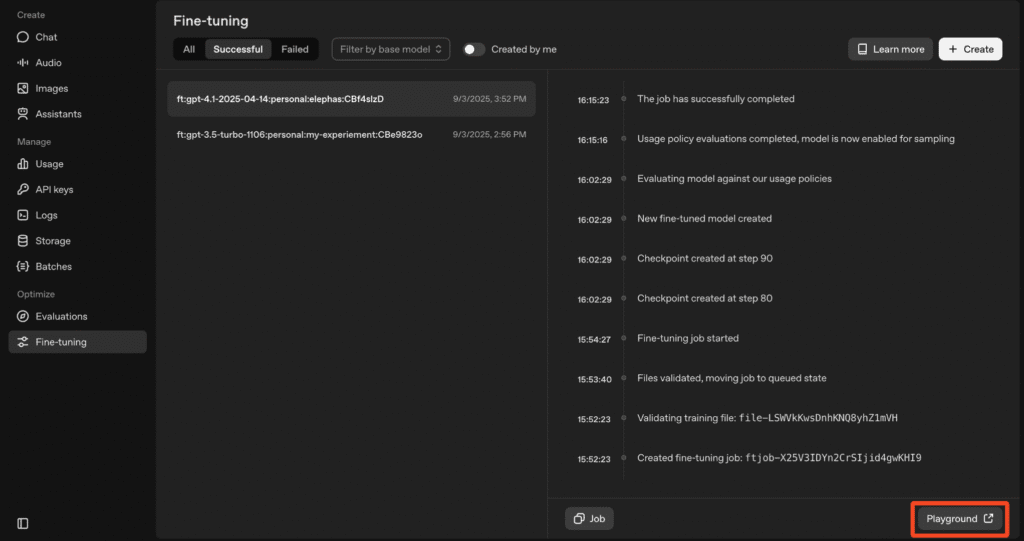
الخطوة 5: بمجرد الانتهاء من تعديل النموذج، يمكنك الضغط على “playground” وبدء استخدام النموذج. يمكنك أيضًا رؤية مقارنة جنبًا إلى جنب بين النموذج المعدل (اللوحة اليمنى) والنموذج العام (اللوحة اليسرى). (هذا يساعد في تقييم التحسينات؛ جرب أسئلة حقيقية لترى الفرق).
كيفية إعداد البيانات للتعديل الدقيق على ChatGPT؟
إنشاء مجموعة بيانات جيدة هو الخطوة الأكثر أهمية في تدريب ChatGPT على بياناتك. جودة مجموعتك تحدد كفاءة النموذج المدرب. يجب أن تكون حذرًا وتتبع الخطوات الصحيحة للحصول على نتائج جيدة. دعونا نبسط هذا: البيانات مثل الوقود للسيارة؛ إذا كانت رديئة، لن تسير السيارة بعيدًا.
الهيكل الأساسي يستخدم ثلاثة أجزاء لكل عينة تدريب: رسالة نظام تحدد سلوك الـ AI، رسالة مستخدم تظهر ما سيسأله الناس، ورسالة مساعد تظهر الرد المثالي الذي تريده. هذا يشبه حوارًا مكتوبًا يتعلم منه الـ AI.
متطلبات مجموعة البيانات (مع شرح مفصل):
- حد أدنى 10 أمثلة: تحتاج OpenAI إلى 10 عينات تدريب على الأقل لبدء التعديل الدقيق؛ أقل من ذلك يفشل العملية. ابدأ بـ 10 جيدة ثم زد تدريجيًا.
- تنسيق متسق: كل مثال يجب أن يتبع الهيكل نفسه بالضبط؛ أي تغيير يمكن أن يسبب أخطاء.
- الجودة على الكمية: أفضل 10 أمثلة رائعة من 50 سيئة؛ ركز على الدقة والواقعية.
- تعليمات واضحة: رسائل النظام يجب أن تقدم إرشادات سلوكية محددة، مثل “كن مهذبًا وموجزًا”.
- حوارات واقعية: رسائل المستخدم يجب أن تطابق أسئلة حقيقية قد يطرحها الناس في عملك.
نموذج مثالي للتنسيق:
{“messages”: [{“role”: “system”, “content”: “أنت وكيل خدمة عملاء مفيد”}, {“role”: “user”, “content”: “ما هي ساعات عملكم؟”}, {“role”: “assistant”, “content”: “نحن مفتوحون من الاثنين إلى الجمعة من 9 صباحًا إلى 6 مساءً بتوقيت الشرق”}]}
{“messages”: [{“role”: “system”, “content”: “أنت مساعد مفيد يقدم معلومات دقيقة عن Elephas، مساعد معرفي لـ Mac وأداة كتابة AI.”}, {“role”: “user”, “content”: “ما هو Elephas؟”}, {“role”: “assistant”, “content”: “Elephas هو مساعد معرفي قوي لـ Mac يغير طريقة التقاطك، تنظيمك، والوصول إلى المعلومات. يساعد مستخدمي Mac في بناء وإدارة نظام معرفتهم الشخصي بميزات مدعومة بالـ AI مثل Super Brain، Smart Write، وأتمتة سير العمل.”}]}
إنشاء ملف JSONL الخاص بك (خطوات مفصلة):
- افتح Visual Studio Code وأنشئ ملفًا جديدًا. (هذا البرنامج مجاني وسهل الاستخدام للتحرير التقني).
- احفظه بامتداد .jsonl بتنسيق JSON lines. (JSONL يعني كل سطر هو كائن JSON مستقل، مما يجعله مناسبًا للبيانات الكبيرة).
- كل سطر يجب أن يحتوي على مثال تدريب كامل واحد. تأكد من عدم وجود مسافات إضافية أو سطور فارغة بين الأمثلة. يجب أن يكون الملف مضغوطًا دون فواصل تنسيق.
تحقق من الصياغة بعناية قبل الرفع. خطأ صغير واحد يمكن أن يفسد عملية التدريب بأكملها. جرب اختبار الملف بأدوات JSON validator عبر الإنترنت للتأكد.
قيود التعديل الدقيق على ChatGPT ومشروعاته
كل من التعديل الدقيق على ChatGPT ومشروعاته لديهما قيود مهمة يجب معرفتها قبل اختيار الطريقة. دعونا نشرح هذه القيود بتفصيل لمساعدتك على تجنب المفاجآت.
قيود التعديل الدقيق على ChatGPT:
يعمل التعديل الدقيق أفضل لمهام محددة مع كميات صغيرة من البيانات. لا يمكنه التعامل مع ملفات كبيرة مثل PDF أو معالجة مجموعات بيانات كبيرة بفعالية. هذه الطريقة مصممة لتعليم ChatGPT الكتابة بأسلوب معين أو التصرف مثل شخص محدد، لا لإطعامه كميات هائلة من المعلومات.
إنشاء بيانات التدريب للتعديل الدقيق عملية صعبة وتستغرق وقتًا طويلًا. يجب تنسيق كل شيء بشكل مثالي بتنسيق JSON lines. حتى خطأ صغير في بياناتك يمكن أن يسبب فشل عملية التدريب بالكامل.
- تعمل فقط مع مجموعات بيانات صغيرة ومحددة.
- لا تستطيع معالجة وثائق أو ملفات كبيرة.
- تتطلب تنسيق بيانات مثالي.
- أخطاء صغيرة تسبب فشل كامل.
- عملية إعداد بيانات تستغرق وقتًا.
- أفضل لتغييرات الأسلوب والسلوك، لا لتخزين المعلومات.
قيود مشروعات ChatGPT:
مشروعات ChatGPT أسهل في الإعداد من التعديل الدقيق، لكنها لديها حدود صارمة على الملفات. يمكنك رفع 20 ملفًا فقط لكل مشروع، مما يقيد كمية المعلومات التي يمكن تضمينها.
النظام يقبل وثائق نصية فقط ولا يعمل مع صفحات الويب أو فيديوهات يوتيوب. بياناتك المرفوعة تبقى ثابتة ولا تتحدث تلقائيًا عند تغيير الملفات الأصلية.
- حد أقصى 20 ملفًا لكل مشروع.
- وثائق نصية فقط مسموحة.
- لا دعم لصفحات الويب أو الفيديوهات.
- البيانات لا تتحدث تلقائيًا.
- تخزين معلومات ثابت.
- خيارات محدودة لحجم الملفات والتنسيقات.
كلا الطريقتين لهما توازن بين سهولة الاستخدام والوظائف، لكن هناك طريقة أفضل بكثير لتدريب ChatGPT على بياناتك وحتى بعض ميزات التكامل، وهي استخدام RAG (التوليد المعزز بالاسترجاع).
ما هو التوليد المعزز بالاسترجاع (RAG)؟
التوليد المعزز بالاسترجاع (Retrieval-Augmented Generation، أو اختصارًا RAG) هو تقنية حديثة في مجال الذكاء الاصطناعي، خاصة في نماذج اللغة الكبيرة (Large Language Models – LLMs) مثل تلك المستخدمة في ChatGPT أو نماذج مشابهة. تهدف RAG إلى تحسين جودة الردود التي يولدها الذكاء الاصطناعي من خلال دمج عملية استرجاع (retrieval) للمعلومات من مصادر خارجية مع عملية التوليد (generation) للنصوص. بدلاً من الاعتماد فقط على المعرفة المخزنة داخل النموذج أثناء تدريبه، يقوم RAG بجلب معلومات ذات صلة في الوقت الفعلي من قاعدة بيانات أو مصادر خارجية، مما يجعل الردود أكثر دقة وموثوقية.
دعنا نستعرض هذا المفهوم بالتفصيل، خطوة بخطوة، مع التركيز على آلية عمله، فوائده، قيوده، وأمثلة عامة لاستخدامه في سيناريوهات يومية أو مهنية.
آلية عمل RAG: كيف يتم دمج الاسترجاع والتوليد؟
يعتمد RAG على دمج نظامين رئيسيين: نظام الاسترجاع (retriever) ونظام التوليد (generator). إليك الخطوات الرئيسية لكيفية عمله:
- تلقي الاستعلام (Query): يبدأ العملية بسؤال أو طلب من المستخدم، مثل “ما هي أحدث التطورات في الطاقة المتجددة؟”.
- عملية الاسترجاع (Retrieval): يقوم النظام بالبحث عن معلومات ذات صلة في قاعدة بيانات خارجية أو مصادر معرفية (مثل وثائق، مقالات، أو قواعد بيانات). هذا يتم عادةً باستخدام تقنيات مثل قواعد البيانات المتجهية (vector databases)، حيث يتم تحويل النصوص إلى متجهات رقمية (embeddings) لقياس التشابه. على سبيل المثال، يحول السؤال إلى متجه، ثم يبحث عن أقرب المتجهات في القاعدة لاسترجاع الوثائق الأكثر صلة.
- معالجة المعلومات المسترجعة: بعد استرجاع الوثائق (مثل فقرات من مقالات أو صفحات من كتب)، يتم تلخيصها أو ترتيبها لتكون مناسبة للنموذج. هذا يمنع إغراق النموذج بكميات هائلة من البيانات.
- عملية التوليد (Generation): يتم إدخال السؤال الأصلي مع المعلومات المسترجعة إلى نموذج اللغة (مثل LLM). يولد النموذج ردًا يعتمد على هذه المعلومات الجديدة، مما يجعله أكثر دقة وحداثة.
- التحقق والتحسين (اختياري): في بعض التطبيقات المتقدمة، يمكن إضافة خطوة للتحقق من دقة الرد أو تكرار العملية إذا لزم الأمر.
هذه العملية تجعل RAG أكثر كفاءة من النماذج التقليدية، حيث لا يحتاج النموذج إلى إعادة تدريب كامل لتحديث المعرفة – يكفي تحديث قاعدة البيانات الخارجية.
الفوائد الرئيسية لاستخدام RAG
يوفر RAG مزايا عديدة تجعله خيارًا شائعًا في تطبيقات الذكاء الاصطناعي:
- تحسين الدقة وتقليل الهلوسة (Hallucination): النماذج التقليدية قد تبتكر معلومات خاطئة إذا لم تكن مدربة عليها. RAG يعتمد على مصادر موثوقة، مما يقلل من هذه المشكلة بنسبة كبيرة.
- الوصول إلى معلومات حديثة ومتغيرة: النماذج المدربة تكون محدودة بتاريخ تدريبها (مثل معرفة حتى عام 2023 في بعض النماذج). RAG يمكنه استرجاع بيانات حديثة من الإنترنت أو قواعد داخلية.
- التخصيص والخصوصية: يمكن استخدامه مع بيانات خاصة دون مشاركتها مع نموذج عام، مما يحافظ على الخصوصية.
- كفاءة في التعامل مع كميات كبيرة من البيانات: بدلاً من تخزين كل شيء داخل النموذج، يسترجع فقط ما هو ضروري، مما يوفر موارد الحوسبة.
- مرونة في التطبيقات: يناسب مجالات متنوعة مثل البحث، الدعم الفني، والتحليل.
القيود والتحديات في استخدام RAG
رغم فوائده، لدى RAG بعض العيوب التي يجب مراعاتها:
- التعقيد في الإعداد: يتطلب بناء قاعدة بيانات متجهية ونظام استرجاع، مما قد يحتاج إلى مهارات تقنية.
- جودة الاسترجاع: إذا كانت عملية البحث غير دقيقة، قد يؤدي ذلك إلى ردود غير ذات صلة.
- التكلفة: في حال استخدام خدمات سحابية، قد تكون هناك تكاليف للبحث والتوليد.
- الاعتماد على المصادر: إذا كانت القاعدة غير محدثة أو تحتوي على معلومات خاطئة، ينعكس ذلك على الرد.
مع التقدم، يتم حل هذه التحديات تدريجيًا من خلال تحسين الخوارزميات.
أمثلة عامة على استخدام RAG
لتوضيح الفكرة، إليك أمثلة عامة من سيناريوهات حقيقية، بدون التركيز على أدوات أو منتجات محددة:
- مساعد دعم عملاء في شركة تقنية: تخيل chatbot يجيب على أسئلة العملاء حول مشكلات المنتج. عندما يسأل مستخدم “كيف أصلح خطأ في البرنامج X؟”، يقوم RAG باسترجاع دليل المستخدم أو مقالات دعم سابقة من قاعدة داخلية، ثم يولد ردًا خطوة بخطوة بناءً عليها. هذا يضمن أن الرد دقيق ومبني على معلومات الشركة الرسمية، بدلاً من تخمين عام.
- أداة بحث علمي أو أكاديمي: في نظام بحثي، إذا سأل باحث “ما هي الدراسات الأخيرة عن تغير المناخ؟”، يسترجع RAG مقالات من قواعد بيانات مثل PubMed أو Google Scholar، ثم يلخصها في رد مترابط. هذا يساعد في الحصول على معلومات حديثة دون الحاجة إلى إعادة تدريب النموذج كل مرة.
- مساعد قانوني أو مالي: في تطبيق للمحامين، يمكن لـ RAG استرجاع قوانين أو حالات قضائية ذات صلة من قاعدة بيانات قانونية، ثم توليد تحليل أو اقتراحات. على سبيل المثال، عند السؤال عن “ما هي الآثار الضريبية لعملية بيع أصول؟”، يجلب RAG نصوص قوانين حديثة ويبني عليها ردًا مفصلاً، مما يقلل من الأخطاء.
- تطبيق تعليمي: في منصة تعليمية، يسأل طالب “شرح نظرية النسبية”، فيسترجع RAG فقرات من كتب دراسية أو مقالات تعليمية، ثم يولد شرحًا مبسطًا مع أمثلة، مما يجعل التعلم أكثر تخصيصًا ودقة.
هذه الأمثلة توضح كيف يمكن لـ RAG تحويل نماذج الذكاء الاصطناعي إلى أدوات أكثر ذكاءً وموثوقية في مجالات متنوعة.
الخاتمة
تدريب ChatGPT على بياناتك الخاصة يفتح أبوابًا واسعة لتحسين الإنتاجية والدقة في عملك اليومي. سواء اخترت Custom GPTs للبساطة، أو Fine-tuning للتخصيص العميق، أو RAG للتعامل مع بيانات كبيرة، فإن الفوائد الرئيسية مثل الإجابات الدقيقة والأسلوب المتسق تجعل العملية تستحق الجهد. ابدأ بخطوات صغيرة، وستجد أن تخصيص AI أمر يمكن تحقيقه بسهولة لتحقيق نتائج مذهلة.