

حكاية الثورة: عندما يكسر “الوميض” احتكار الكبار
Xiaomi MiMo-V2-Flash : تخيل أنك مطور برمجيات طموح، تعمل ليل نهار على بناء تطبيق أحلامك. فجأة، تصطدم بجدار التكاليف الباهظة!! فاستخدام نماذج الذكاء الاصطناعي المتطورة مثل Claude 3.5 أو GPT-4o يكلفك ثروة مع كل سطر برمج يكتبه النموذج أو كل سؤال منطقي يجيب عليه. تشعر بالإحباط، فكيف لمشروع ناشئ أن ينافس الشركات الكبرى في ظل هذه التكاليف؟
في هذه اللحظة بالذات، يظهر “وميض” من الشرق. ليس مجرد وميض عابر، بل هو إعصار تقني أطلقته شركة شاومي (Xiaomi) تحت اسم Xiaomi MiMo-V2-Flash. فجأة، تتغير قواعد اللعبة تماماً. نموذج مفتوح المصدر، يمتلك قدرات برمجية تضاهي أقوى النماذج المدفوعة، وبسرعة جنونية تجعلك تشعر وكأنك تتحدث مع إنسان حقيقي، والأهم من ذلك كله.. التكلفة تكاد تكون “ببلاش” مقارنة بالمنافسين!
لقد قررت شاومي دخول سباق الذكاء الاصطناعي “بقلب ميت”، متجاوزة التوقعات بنموذج لا يكتفي بالمنافسة، بل يسعى لإعادة تعريف مفهوم “الذكاء الاصطناعي للجميع”. فهل نحن أمام مجرد “شو” دعائي جديد، أم أن MiMo-V2-Flash هو فعلاً الصفقة الرابحة التي انتظرها المطورون والمستخدمون طويلاً؟ دعونا نغوص في أعماق هذا الوحش التقني ونكتشف الحقيقة.
ما هو Xiaomi MiMo-V2-Flash؟ المواصفات التقنية
يُعد Xiaomi MiMo-V2-Flash نموذجاً لغوياً ضخماً يعتمد على معمارية “خليط الخبراء” (Mixture-of-Experts – MoE). يمتلك النموذج إجمالي 309 مليار بارامتر، ولكن بفضل ذكاء التصميم، يتم تنشيط 15 مليار بارامتر فقط لكل طلب، مما يجعله يجمع بين القوة الهائلة والكفاءة العالية في استهلاك الموارد .
الجدول التقني: مواصفات MiMo-V2-Flash مقابل المنافسين
| الميزة | Xiaomi MiMo-V2-Flash | Claude 3.5 Sonnet | GPT-4o |
|---|---|---|---|
| المعمارية | MoE (309B Total / 15B Active) | Dense (غير معلن) | MoE (غير معلن) |
| طول السياق (Context) | 256,000 توكن | 200,000 توكن | 128,000 توكن |
| السرعة (Generation) | فائقة (بفضل تقنية MTP) | سريعة | سريعة جداً |
| التكلفة | مفتوح المصدر / تكلفة API ضئيلة | مدفوع / API مرتفع التكلفة | مدفوع / API مرتفع التكلفة |
| الوصول | محلي (Local) + سحابي | سحابي فقط | سحابي فقط |
سر السرعة: تقنية Multi-Token Prediction (MTP)
أحد أكبر الابتكارات في Xiaomi MiMo-V2-Flash هو دمج وحدة Multi-Token Prediction (MTP) بشكل أصلي. على عكس النماذج التقليدية التي تتوقع كلمة واحدة في كل مرة، يقوم MiMo بتوليد عدة كلمات (Tokens) في وقت واحد. هذه التقنية تضاعف سرعة التوليد بمقدار 3 مرات تقريباً، مما يجعله يمثالياً لمهام البرمجة والدردشة الفورية التي تتطلب استجابة سريعة جداً.
تجربة الأداء: هل MiMo-V2-Flash قوي في البرمجة فعلاً؟
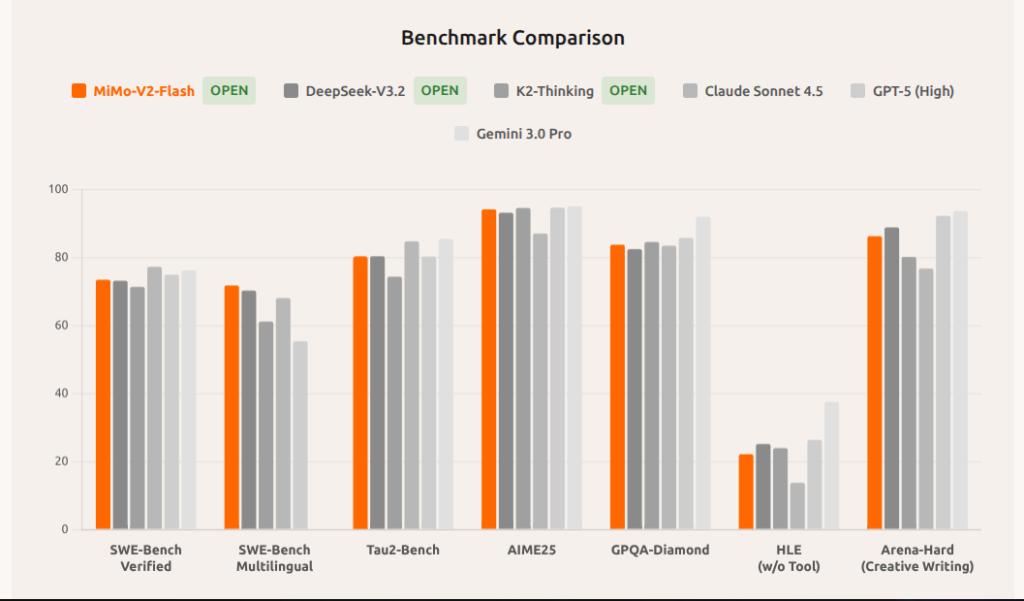
عندما يتعلق الأمر بالبرمجة، فإن الأرقام لا تكذب. في اختبارات SWE-Bench (التي تقيس قدرة النموذج على حل مشكلات برمجية حقيقية من GitHub)، حقق MiMo-V2-Flash نتائج مذهلة تضاهي Claude 3.5 Sonnet، ولكن بجزء بسيط جداً من التكلفة (حوالي 2.5% فقط من سعر Claude) .
نقاط القوة في البرمجة والمنطق:
- فهم السياق الطويل: بفضل نافذة سياق تصل إلى 256 ألف توكن، يمكن للنموذج قراءة ملفات برمجية ضخمة وفهم العلاقة بين أجزاء الكود المختلفة دون أن يفقد التركيز.
- دقة الأكواد: أثبت النموذج كفاءة عالية في كتابة أكواد React و Tailwind CSS، ويمكن تجربته مباشرة عبر منصات مثل CodePen للتأكد من جودة المخرجات .
- الأسئلة المنطقية: يتفوق النموذج في حل المسائل الرياضية المعقدة والأسئلة التي تتطلب تفكيراً منطقياً متسلسلاً، متجاوزاً نماذج أكبر منه بكثير في عدد البارامترات النشطة .
كيف تستخدم Xiaomi MiMo-V2-Flash “ببلاش”؟
أجمل ما في هذا النموذج هو مرونة الوصول إليه. شاومي لم تكتفِ بإطلاقه، بل وفرت أدوات تجعل استخدامه متاحاً للجميع:
1. تجربة مباشرة عبر Xiaomi MiMo Studio
يمكنك البدء فوراً بتجربة النموذج عبر الموقع الرسمي Xiaomi MiMo Studio. الواجهة بسيطة، سريعة، وتسمح لك باختبار قدرات النموذج في الدردشة والبرمجة دون الحاجة لأي إعدادات معقدة.
2. التشغيل المحلي عبر LM Studio (للمحترفين والخصوصية)
إذا كنت تهتم بخصوصية بياناتك أو تريد العمل دون اتصال بالإنترنت، يمكنك تحميل النموذج من Hugging Face وتشغيله محلياً على جهازك باستخدام برنامج LM Studio. هذه الطريقة تضمن لك تحكماً كاملاً وتكلفة تشغيل صفرية (فقط استهلاك الكهرباء وموارد جهازك!).
متطلبات التشغيل المحلي: كم تحتاج لتشغيل Xiaomi MiMo-V2-Flash على جهازك؟
على الرغم من أن Xiaomi MiMo-V2-Flash هو نموذج مفتوح المصدر و”مجاني” من حيث التكلفة المباشرة، إلا أن تشغيله محلياً يتطلب قوة حوسبة كبيرة نظراً لحجمه الهائل (309 مليار بارامتر إجمالي). ومع ذلك، فإن تقنيات الضغط (Quantization) الحديثة تجعل هذا الحلم ممكناً على أجهزة المستخدمين المتقدمين.
لتشغيل النموذج بكفاءة، خاصة في مهام البرمجة والسياق الطويل، يجب مراعاة الحد الأدنى من المتطلبات التقنية التالية، والتي تعتمد على استخدام تقنية الضغط (مثل Q4 Quantization) لتقليل حجم النموذج في الذاكرة:
| المكون | الحد الأدنى الموصى به (مع الضغط Q4) | ملاحظات |
| ذاكرة الفيديو (VRAM) | 24 جيجابايت | يفضل استخدام بطاقات رسومية مثل RTX 3090 أو RTX 4090 أو ما يعادلها. يمكن استخدام بطاقتين (2x 16GB) معاً. |
| ذاكرة النظام (RAM) | 64 جيجابايت | يوصى بـ 128 جيجابايت لضمان سلاسة العمل مع السياقات الطويلة جداً. |
| المعالج (CPU) | معالج حديث متعدد النواة (Multi-Core) | يفضل معالجات Ryzen 7 أو Intel Core i7 (الجيل العاشر وما فوق) لدعم عمليات النقل السريعة. |
ملاحظة هامة: هذه المتطلبات هي للتشغيل الفعال والسريع. إذا كنت تخطط لتشغيل النموذج بدقة كاملة (FP16)، فستحتاج إلى مجموعة من وحدات معالجة الرسوميات (GPU Cluster) مثل 4x A100 أو H100، وهو ما يتجاوز قدرات الأجهزة الشخصية. لذلك، فإن استخدام برامج مثل LM Studio التي تدعم الضغط (Quantization) هو المفتاح للاستفادة من قوة MiMo-V2-Flash على جهازك الشخصي
3. للمطورين عبر Hugging Face
يوفر رابط النموذج على Hugging Face كل الملفات اللازمة للمطورين لدمج MiMo-V2-Flash في تطبيقاتهم الخاصة، مع دعم كامل لمكتبة Transformers و Safetensors .
4- مفتاح API: الوصول السحابي بتكلفة “شبه مجانية”
إذا كان التشغيل المحلي يتطلب أجهزة قوية، فإن شاومي لم تنسَ المطورين الذين يعتمدون على البنية التحتية السحابية. يتيح لك Xiaomi MiMo-V2-Flash الوصول إليه عبر واجهة برمجية (API) من خلال منصة Xiaomi MiMo API Open Platform، مما يجمع بين قوة النموذج ومرونة السحابة.
تكلفة لا تُصدق: المنافسة بـ 2.5% من السعر
النقطة الأكثر إثارة في استخدام API هي التسعير الذي أطلقته شاومي، والذي يهدف بوضوح إلى إحداث ثورة في السوق. يمكن تلخيص التكلفة والمقارنة كالتالي:
| النموذج | تكلفة الإدخال (لكل مليون توكن) | تكلفة الإخراج (لكل مليون توكن) |
|---|---|---|
| Xiaomi MiMo-V2-Flash | 0.10 دولار | 0.30 دولار |
| GPT-4o (OpenAI) | 5.00 دولارات | 15.00 دولاراً |
| Claude 3.5 Sonnet (Anthropic) | 3.00 دولارات | 15.00 دولاراً |
كما يظهر من الجدول، فإن تكلفة استخدام Xiaomi MiMo-V2-Flash عبر API هي جزء ضئيل جداً من تكلفة النماذج المنافسة، حيث يمكن أن يكون أرخص بما يصل إلى 50 مرة من GPT-4o في الإدخال. هذا التسعير العدواني يجعله الخيار الأمثل للمطورين الذين يبنون تطبيقات ذات حجم كبير وتتطلب استهلاكاً عالياً للتوكنات، مما يضمن لهم أداءً عالياً بتكلفة تكاد تكون “شبه مجانية”.
كيفية الاستخدام
للبدء، يجب عليك التسجيل في Xiaomi MiMo API Open Platform للحصول على مفتاح API الخاص بك. بعد ذلك، يمكنك دمج النموذج في تطبيقاتك باستخدام طلبات HTTP بسيطة، أو عبر مكتبات LLM شائعة مثل LiteLLM التي تدعم نموذج شاومي بشكل مباشر. هذا يضمن أن يتمكن المطورون من الانتقال بسهولة من النماذج الأخرى إلى MiMo-V2-Flash دون تغييرات جذرية في الكود [9].
رأي صريح: هل هو “صفقة رابحة” أم مجرد “شو”؟
بعد تحليل المواصفات وتجارب المستخدمين، يمكن القول بثقة أن Xiaomi MiMo-V2-Flash هو صفقة رابحة بكل المقاييس، خاصة للمطورين والشركات الناشئة.
- لماذا هو رابح؟ لأنه يكسر حاجز التكلفة دون التضحية بالجودة. أن تحصل على أداء يقترب من Claude 3.5 Sonnet في البرمجة وبشكل مفتوح المصدر هو إنجاز تقني هائل.
- هل ينافس العمالقة؟ نعم، في مهام محددة مثل البرمجة والمنطق والسياق الطويل، MiMo هو منافس شرس جداً. أما في المهام الإبداعية العامة جداً، فقد تظل النماذج الكبرى مثل GPT-4o تمتلك أفضلية طفيفة في “اللمسة البشرية” والتنوع الثقافي.
الخلاصة: مستقبل الذكاء الاصطناعي في يد الجميع
دخول شاومي لسباق الذكاء الاصطناعي بنموذج مثل Xiaomi MiMo-V2-Flash هو رسالة واضحة للعالم: “الذكاء الاصطناعي القوي لا يجب أن يكون حكراً على من يملك المال”. بفضل معمارية MoE المبتكرة وتقنية MTP الثورية، أصبح بإمكان أي مطور الآن امتلاك “عقل إلكتروني” جبار على جهازه الخاص.
إذا كنت تبحث عن أداة تساعدك في تطوير تطبيقاتك بأقل تكلفة، أو تريد استكشاف آفاق جديدة في الذكاء الاصطناعي دون قيود الاشتراكات الشهرية، فإن MiMo-V2-Flash هو وجهتك القادمة. لا تتردد في تجربته اليوم وشاركه مع زملائك المطورين، فالثورة التقنية الحقيقية هي التي تبدأ من أدوات متاحة للجميع.



